Db2 Columnar Database Next Generation Insertion - Improvements on Trickle Insertion and Data Loading
WRITTEN BY RON LIU
Next Generation INsertion (NGIN) was designed to enhance insertion performance and reduce log space usage. The NGIN enhancements mainly covered three parts, bulk insertion, trickle feed insertion, and bulk load. NGIN bulk insertion had been enabled prior to Db2 11.5.4. In subsequent releases, NGIN trickle insertion, and some other new features were enabled and leveraged the NGIN infrastructure, that include LOAD utility enhancement, automatic recompress feature for tables enhancement, and page-based string compression (more details in a separate article https://www.idug.org/news/db2-columnar-database-page-based-string-compression). NGIN trickle insertion has been enabled since Db2 11.5.6.
Registry Variables
Db2 warehouse does not support fallback so new features are always enabled by default. For Db2 customers, if you are on 11.5.7 or later and have no plan to fallback prior to 11.5.7, it is recommended that you set the following registry variables together for overall best performance and compression. Please reference this article for details (https://www.idug.org/blogs/joe-geller1/2023/03/20/columnar-data-engine-cde-storage-new-feature)
db2set DB2_COL_INSERT_GROUPS=YES
db2set DB2_COL_STRING_COMPRESSION="UNENCODED_STRING:YES"
db2set DB2_COL_SYNOPSIS_SETTINGS="DEFER_FIRST_SYNOPSIS_TUPLE:YES"
NGIN Trickle Insertion
Columns of a Db2 BLU table are partitioned into column groups, wherein each column belongs to exactly one ColumnGroup. Internally, nullability is in a separate null indicator column, so nullable columns define a ColumnGroup containing at least two columns: the nullable column and its internal null indicator. ColumnGroup data are stored in fixed-size pages. A larger unit of contiguous storage, called an extent, which contains a fixed number of pages for a given table, is the unit of allocation for BLU storage. Prior to NGIN, each extent contains the data of one column group only. While talking about performance, much impact is true for all table sizes with trickle insert - the benefit to small tables is to reduce extent/page overhead that normalizes out with larger tables. NGIN trickle insertion was designed to address trickle feed performance. Rows coming from small inserts will not be separated into different pages and extents for each ColumnGroup. Instead, multiple ColumnGroups will be combined to a so-called InsertGroup which constitutes an alternate way of defining the relationship of ColumnGroups to columnar data pages. Under this new design, all ColumnGroups associated with the same InsertGroup will be stored on the same CDE data page. There can, of course, be multiple InsertGroups for a single table, their number being dependent on the total number of columns in the table and the maximum number of ColumnGroups that fit on a page given its size. InsertGroup page will perform an efficient split of existing InsertGroup pages into separate ColumnGroup pages if the data inserted into the table exceeds some thresholds. But for small inserts (normally no more than a few hundred rows and fall below the threshold) will remain in the InsertGroup form. Hence the NGIN design for trickle insertion can effectively avoid having just a few rows on the same page or extent for small tables. The following diagram shows how NGIN handles trickle insertion and bulk insertion in a very high level.
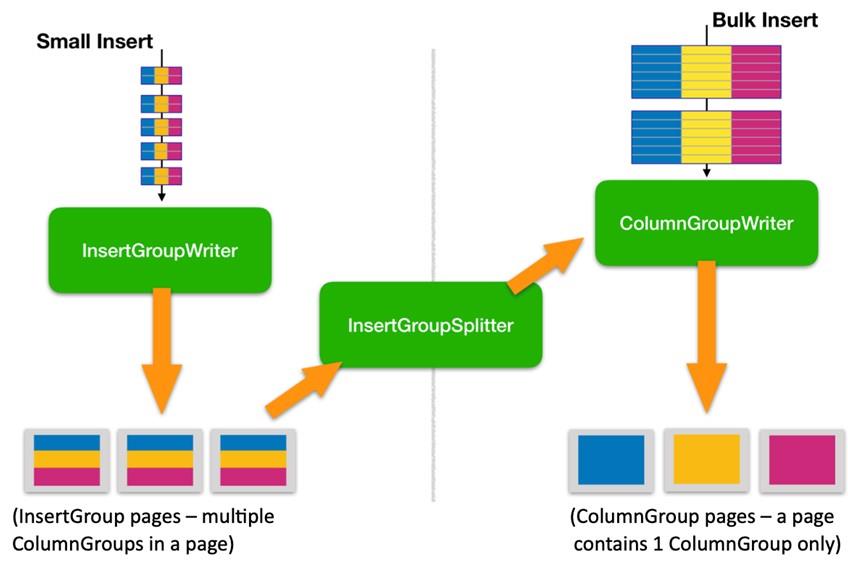
NGIN Trickle insertion also reduced memory footprint for workloads with heavy trickle inserts and updates, reduces log volumes, and reduces CPU consumption for insertion workloads. It also reduces storage usage for small tables. The following are the highlights for performance enhancements with NGIN trickle insertion.
- Dramatic reduction in storage space usage by small tables (e.g., a test table storing store locations information reduced physical size from 1.5GB to 130MB in a 1/3 Rack IIAS)
- Will reduce storage consumption for any customer with small tables, especially ones with large number of columns
- Test results in insert scenarios
- Insert performance enhancement - 7% improvement for a massive insertion workload, 4% for a 'large trickle' workload, 16-23% for Insert from Sub Select
- Dramatic reduction in log volume and dirty page writes (sample workload of massive transactions showed 78% log reduction and 44% less page writes, sample workload mimics a healthcare provider showed 70% log reduction)
- Page-based string compression for trickle inserts – Improved from no compression to 2.5x compression for unencoded string data for the CUSTOMER table
- Query workload results (ran in a 1/3 Rack IIAS)
- Simple sales analytics workload: query performance not impacted with data inserted through trickle feed
- Complex sales analytics workload: same
- Further improvements with 11.5.7
- 37% faster insert performance for in-house trickle insertion workload
- 46% reduction in latching for in-house stress contention test
- Further improvements might be achieved with higher threshold settings for some workloads
LOAD Utility Enhancement
The LOAD utility was enhanced to leverage the NGIN bulk insertion infrastructure so page-based string compression can be used. This leads to significant storage saving for some tables with string data.
Table loaded with NGIN disabled

Same table loaded with NGIN enabled
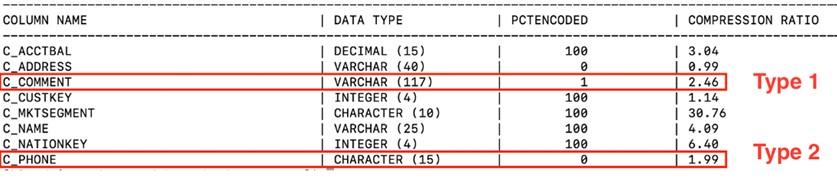
As shown in the above tables, both the C_COMMENT and C_PHONE columns were not compressed if data were loaded with NGIN disabled. With the LOAD utility enhanced to use the Next Generation Insert infrastructure (NGIN enabled), these columns were compressed (through page-based string compression).
Besides compression improvements, LOAD utility enhancement that leveraged NGIN also improved load performance. IBM testing team reported performance improvement of up to 27% in their LOAD intensive workloads.
Automatic Recompress feature for tables enhancements
If an insert operation is used to populate a table, automatic creation of the compression dictionaries begins once a threshold count of rows are inserted into the table. Rows that are inserted before the compression dictionaries are created populated and are not initially compressed. Rows inserted after dictionary creation will be compressed through the Automatic Recompress feature. This feature now can use the NGIN bulk insertion infrastructure and leverage page-based string compression. Reduced memory usage, improved performance and compression were observed.