Modernizing Db2 Containerization Footprint with Db2U
Containerization takes Db2 to the world of Cloud Paks, Red Hat OpenShift, Public Cloud Kubernetes platforms (AWS, Azure, Google Cloud and IBM Cloud), and other Kubernetes flavours (Rancher). We are moving at a fast pace; we will bring you up to speed and share the next steps of our journey forward in this article.
There are numerous references to future product plans, deliverables and support statements throughout this article which are subject to notes[1], notices and disclaimers[2] mentioned at the end.
Evolution of Db2 Containerization
Looking back, it is hard to believe Db2 has been available in a Docker/OCI container format since mid-2016 in the form of Db2 Warehouse (a.k.a. dashDB Local). Figure 1 below, depicts the journey of Db2 containerization -- how it evolved from a monolithic Docker/OCI container to a full-fledged Kubernetes-native microservice adapting Operator pattern for managing the Db2 engine lifecycle.
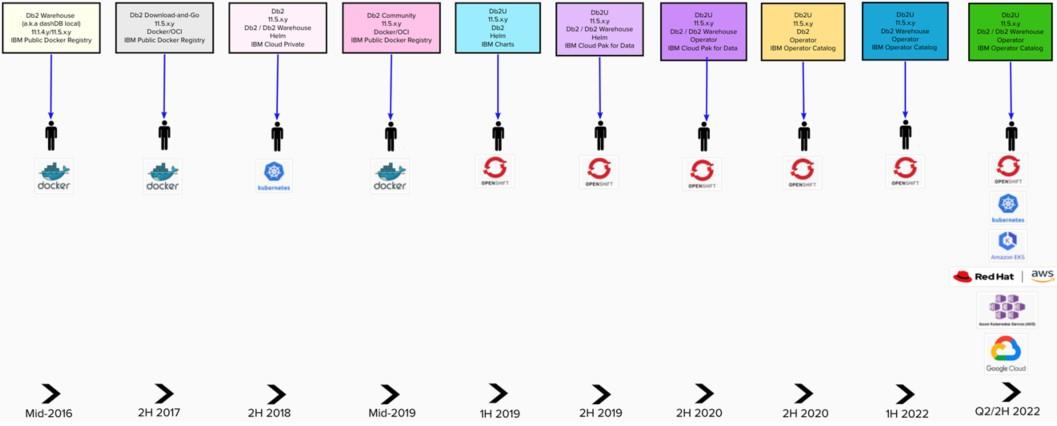
Figure 1: Evolution of Db2 containerization
Db2U Architecture
In order to understand where Db2U is heading, lets first examine the architecture of the current iteration - especially the underlying Kubernetes resource model.
Db2U Operator is a “Go” Kubernetes custom controller implementation, leveraging Operator Framework, Kubernetes client-go (Go clients) and controller-runtime (common controller libraries), and designed to manage (Create, Delete, Update, Get, List) the lifecycle of a Custom Resource (CR) of type (Kind)called Db2uCluster. This CR under-the-hood represents a collection of Kubernetes resources such as StatefulSets, Secrets, ConfigMaps, PersistentVolumeClaims and so on.

Figure 2: Db2U Architecture – Kubernetes Resource Model
There are three routes a user can take to create an instance of Db2uCluster CR:
- On an IBM Cloud Pak for Data (CP4D) platform, use the CP4D UI, which will use the underlying CPD provisioning layer to generate the CR spec based on the user inputs and manage the lifecycle of this CR instance
- On OpenShift platform use the OCP control plane UI to define the Db2uCluster CR schema fields and manage the lifecycle of this CR instance
- On both Kubernetes and OpenShift platforms, define the Db2uCluster CR schema fields in YAML format and manage the lifecycle of this CR instance
End of the day, regardless of the route taken, what Db2U Operator acts on is an API resource of Kind called Db2uCluster.
In the current Db2U architecture, Db2uCluster CR encapsulates following Kubernetes API objects (resources):
- StatefulSet resource: Db2 database engine pods and ETCD pods
- Job resource: One-time tasks, such as instdb, restore-morph and update-upgrade jobs
- Deployment resource: tools, Add-Ons (Db2 REST, Graph and Data Replication), optional LDAP pod
When a StatefulSet is used, there are certain constraints that comes along with it, such as:
- Each Pod in a StatefulSet is rendered from the same Pod Template What that means is, all pods are identical in-terms of their Spec, such as resource requirements (E.G., memory, CPU limits). This prevents for example, the ability to dedicate more resources to the Db2 engine catalog pod over other pods in Warehouse deployments.
- The persistent volumes for Db2 database storage are rendered using Volume Claim Templates (VCT) facility in a StatefulSet. VCT volume name rendering is directly tied to StatefulSet Pod identity and hence automatically generated at the time of the StatefulSet That is, there is little control over the naming convention of Volume Claims generated via VCTs, which makes it quite cumbersome to manage more than one volume-per-storage area. For example, in current iteration of Db2U, only one persistent volume per Db2 engine Pod can be attached for Db2 database storage, even when there can be multiple logical Db2 partitions running inside that Pod.
Next Generation of Db2U – Key Objectives
Going from being the inaugural project for Cloud Native Computing Foundation (CNCF) in 2016, to the first project to graduate two years later, Kubernetes has seen an explosive growth in adaptation within just a few years. Along with that there is a significant trend in moving workloads to various flavours of Kubernetes including what is offered by various public cloud providers such as AWS EKS, Azure AKS, Google GKE, IBM IKS and so on.
Db2U which embraced Kubernetes and by extension OpenShift nearly 3+ years ago, is also changing to align more closely with these public cloud provider environments as well as bring the same benefits to on-prem clouds often sandboxed behind self-service (SaaS-like) portals.
With that, we focused Db2U next generation along these key capabilities:
- Support for large-scale data warehouses on Public Cloud Provider Infrastructure and on-prem
- Improve support for horizontal scaling
- A cloud-native Day 2 user experience aligning with modern dev-Ops/Git-Ops paradigms – I.E., simply interact with Kubernetes API vs Db2 via CLP. Key area for near-to-midterm includes:
- backup, restore and snapshot capabilities
- audit
- centralized logging
Core Functionality Changes
The most fundamental change was switching from a StatefulSet API object to a new CR Kind called Db2uEngine to manage the lifecycle of Db2U engine Pods. This was achieved via a new controller that was essentially a “drop-in” replacement for a StatefulSet controller; but uses Pod API resource to manage the lifecycle of Db2U engine Pods while providing additional capabilities we need.

Figure 3: Managing Db2U Pod lifecycle using Db2uEngine Custom Resource
With this new architecture, next generation Db2U:
- Can support attaching a unique storage volume per each Db2 database partition. This will allow an end-to-end alignment of Db2 Warehouse MPP shared-nothing architecture all the way from the process stack down to the storage subsystem.
- Can define Pod specifications individually, for example give more compute/memory resources to Db2 catalog Pod.
At a high level, two key things have changed in the architecture diagram depicted in Figure 1:
- Lifecycle of underlying Db2U Kubernetes resources will be managed by a new CR Kind called Db2uClusterV2 instead of Db2uCluster. The next gen Db2U Operator will continue to support both CR kinds for the foreseeable future.
- Instead of using a StatefulSet to manage the lifecycle of Db2 engine pods, an instance of Db2uEngine CR will take over the same responsibilities on-top-of the new capabilities mentioned before.
Day 2 Operations - Delivering a Cloud-native User Experience
Another key aspect of the new capabilities that will be delivered in 2H 2022/1H 2023 is centered around transforming common Day 2 administrative tasks such as backup-and-restore, audit, central logging to an interaction with Kubernetes API rather than running native Db2 CLP commands inside a Db2 engine Pod. This will elevate the ability to easily “plug-in” to an on-prem service portal to provide a more of a SaaS-like experience.
A cloud-native self-service approach to Db2 backup-and-restore
In the current iterations of containerized versions of Db2, backup-and-restore (BAR) is driven by executing a kubectl exec or oc exec (on OpenShift) to run Db2 BAR CLP commands within a Db2 engine container environment and examining the CLP output.
Now imagine a Kubernetes CR Kind called Db2uBackup that allows specifying backup attributes such as, scope (database, schema, etc.), type (online, offline, etc.), vendor (disk, TSM in the future, etc.), and a schedule. All you need to do is create an instance of this CR. When the controller responsible for the lifecycle of this CR Kind reconciles this CR instance, it’ll trigger an API call to the Db2u engine catalog pod to kick-off Db2 backup back end automation, and report the status in the Status field of the CR instance.
A restore operation would then be simply driven by a different CR Kind called Db2uRestore that includes a reference to the Db2uBackup CR instance allowing it to access backup settings used beforehand.
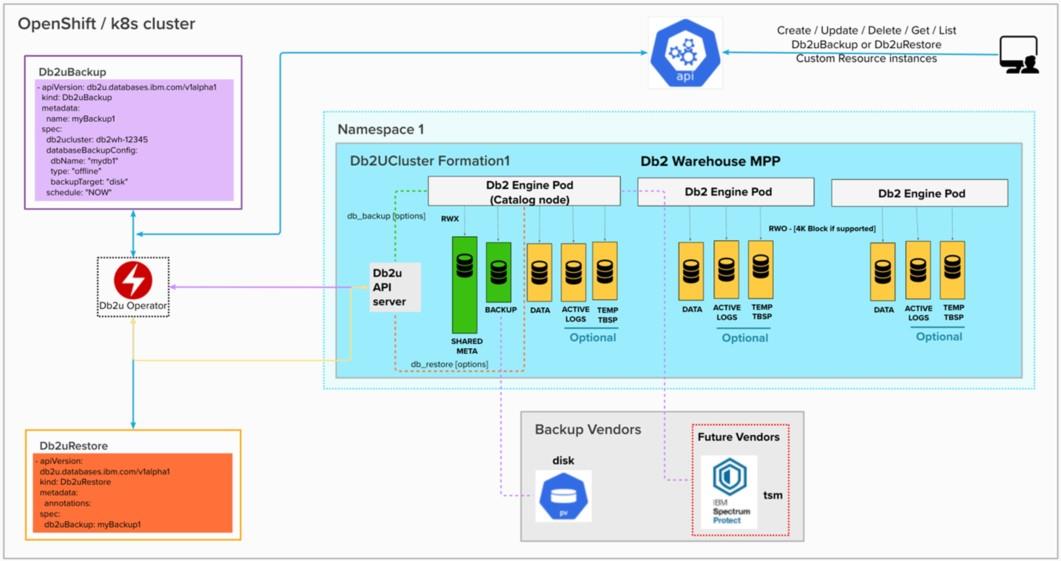
Figure 4: A Kubernetes controller driven approach to Db2 backup-and-restore
Enabling and managing Db2 audit made easy
If you need to enable Db2 audit capabilities in a Db2U deployment today, you can do that by executing into the Db2 engine container (catalog pod) and then setting up audit policies and all the required changes that is needed to enable it. In addition, you are also responsible for managing the audit file storage, archiving etc.
Another exciting feature that we are working on is to expose Db2 audit capability via a new CR Kind called Db2uAudit. You can simply create a CR instance that allows you to choose the pre-built audit policy or define a custom one, set the interval to execute Db2 audit facility. When this CR instance is reconciled by the controller responsible for this CR Kind, it’ll trigger an API call to the backend automation to enable Db2 audit as well as manage audit log storage automatically.

Figure 5: Kubernetes controller driven approach to Db2 Audit facility
Integrating with Central Logging and Metrics Services
Many organizations moving towards cloud-native microservice/SaaS-like delivery models are trying to adapt a centralized log management strategy for more streamlined dev-Ops. For example, Prometheus can be deployed into their private cloud environment to analyze application logs and produce alerts and metrics. Similarly, Elastic Stack (ELK) can be deployed for a full-featured Kubernetes log collection, querying, and presentation of the application logs.
Db2U will enable a new log collection, formatting and streaming facility by expanding the existing “add-On” ecosystem. This new logging Add-On will allow users to specify a centralized-logging service endpoint, interval stream logs, format for each logging type (Db2 audit in 2H 2022, db2 diagnostic/built-in HA logs in 2023) directly in the Db2uCluster (or the upcoming Db2uClusterV2) CR schema via addOns. Based on the logging type specified, a scraper will run in Db2 engine catalog pod to capture a slice of the log file and stage into a shared volume. A Fluentd side-pod will periodically consume this log and stream to the endpoint specified.
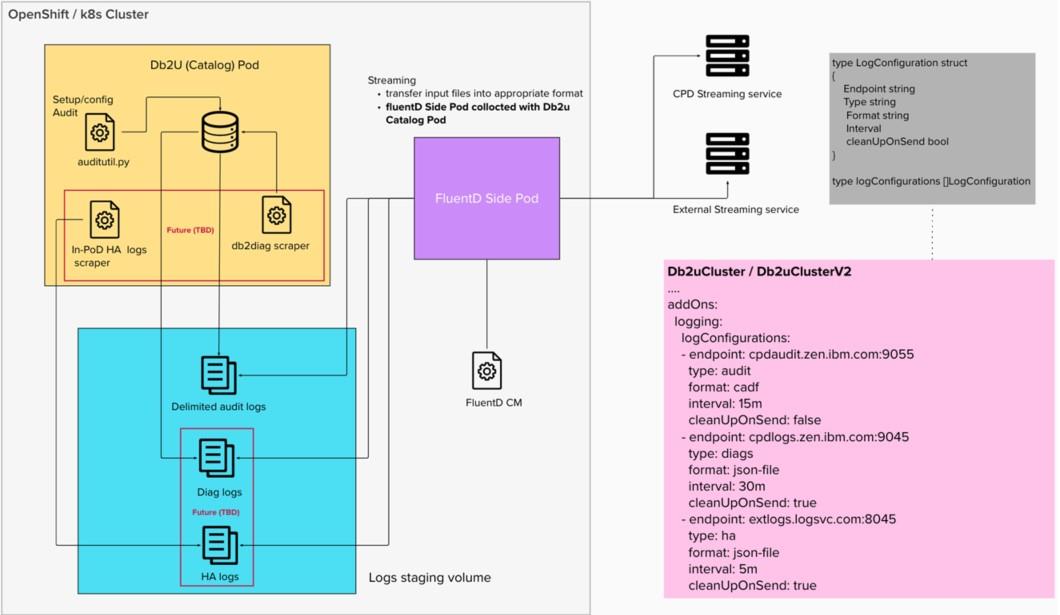
Figure 6: Expanding Db2U ecosystem with a central logging Add-On
Perfectly Aligned with Public Cloud Provider Infrastructure
Numerous organizations have either moved or currently in the process of moving their stateless and stateful applications such as relational databases onto public cloud Kubernetes platforms. Aligning with this move-to-cloud trend, Db2U team has identified support for these cloud provider Kubernetes flavours as one the key priorities in the 2022 roadmap.
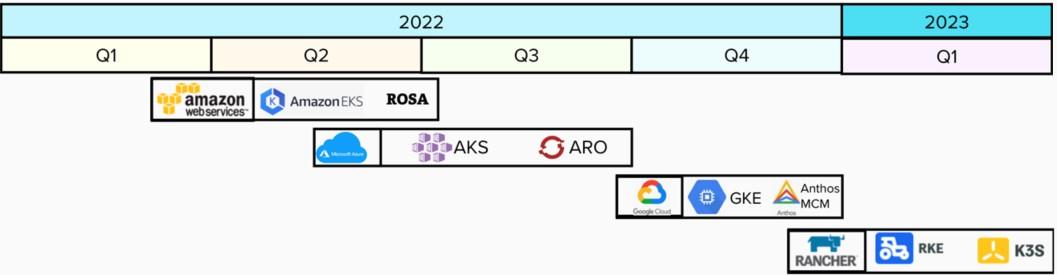
Figure 7: Db2U 2022/23 roadmap to supporting public cloud Kubernetes platforms
A specific area of interest is the ability to deploy Db2U using storage volumes provisioned by each cloud platform’s native Kubernetes Container Storage Interface (CSI) providers. For example, on AWS Elastic Kubernetes Service (EKS), we would deploy Db2U using CSI provider for Elastic File System (EFS) to provision shared (ReadWriteMany) metadata volume, and CSI provider for Elastic Block Storage (EBS) to provision Db2 database storage volumes (ReadWriteOnce). More importantly, we plan to publish a reference architecture in the Db2 Knowledge Centre for each of these public cloud Kubernetes platforms. The planned format for these reference architectures, will include topics such an overview of the high-level architecture including a topology diagram, sizing guidelines, sample end-to-end deployment scenario, high availability and disaster recovery considerations, and so on.
Links
- Db2 containerized deployments on Knowledge Center
- Kubernetes documentation
- OpenShift documentation home
- IBM Cloud Pak for Data portal
[1] Please Note:
- IBM’s statements regarding its plans, directions, and intent are subject to change or withdrawal without notice and at IBM’s sole discretion.
- Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision.
- The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract.
- The development, release, and timing of any future features or functionality described for our products remains at our sole discretion.
- Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user’s job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.
[2] Notices and Disclaimers
- © 2022 International Business Machines Corporation. No part of this document may be reproduced or transmitted in any form without written permission from IBM.
- S. Government Users Restricted Rights — use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM.
- Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. This document is distributed “as is” without any warranty, either express or implied. In no event, shall IBM be liable for any damage arising from the use of this information, including but not limited to, loss of data, business interruption, loss of profit or loss of opportunity. IBM products and services are warranted per the terms and conditions of the agreements under which they are provided.
- IBM products are manufactured from new parts or new and used parts.
In some cases, a product may not be new and may have been previously installed. Regardless, our warranty terms apply.” - Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice.
- Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary.
- References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in which IBM operates or does business.
- Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or their specific situation.
- It is the customer’s responsibility to ensure its own compliance with legal requirements and to obtain advice of competent legal counsel as to the identification and interpretation of any relevant laws and regulatory requirements that may affect the customer’s business and any actions the customer may need to take to comply with such laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer follows any law.
Aruna De Silva is the architect for Db2 on IBM Cloud Pack for Data, OpenShift and Kubernetes (a.k.a. Db2U Universal Container) offering with over 16 years of database technology experience. He is based off IBM Toronto software laboratory.
Since 2015, he has been actively involved with modernizing Db2 — bringing Db2 Warehouse (a.k.a dashDB local), the first containerized Db2 solution out into production in 2016. Starting from early 2019, he has been primarily focused on bringing the success of Db2 Warehouse into cloud native platforms such as OpenShift and Kubernetes while embracing micro service architecture and deployment patterns. With that, he played a key role in the Db2 modernization journey on IBM Cloud Pack for Data, OpenShift and Kubernetes via Db2 Universal Container (Db2U).